22. Natural Language Processing#
Natural Language Processing (NLP) is an important part of Machine Learning. In Python there is a good library called as Natural Language Toolkit (NLTK).
The NLTK toolkit can be installed first with PIP/Conda
pip install nltk or
conda install nltk
For downloading and parsing web content, it is also necessary to install packages
pip install requests beautifulsoup4 or
conda install requests beautifulsoup4
Then import it and download some additional components of nltk and sample data (corpus). You can even download them all, since they do not require huge amount of disk space
Regular experssions are also very usefull for many kinds of general text processing. Learn how to use Python RE.
# You can use an interactive console side by side with the notebook
# by starting the Qt-console
%qtconsole
# Standard libraries to be used
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('fivethirtyeight')
# Library for making web requests and parsing text from web page
# These are needed now only, because we want to get text from the
# web page
import requests
from bs4 import BeautifulSoup
# A regular experssion library. This is very usefull for text processing
import re
# Import the NLTK library
import nltk
# Run this, if you want to download more modules from the net
# nltk.download()
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 16
13 import re
15 # Import the NLTK library
---> 16 import nltk
18 # Run this, if you want to download more modules from the net
19 # nltk.download()
ModuleNotFoundError: No module named 'nltk'
22.1. Read data from a web page#
## Read INCUBATE project's web page
url='https://www.uwasa.fi/en/research/projects/indoor-navigation-cubesat-technology-incubate'
html_text = requests.get(url).text
# And parse the text out from the page
soup = BeautifulSoup(html_text, 'html.parser')
print(soup.title)
print("")
# Use regular expressions to replace a strig of spaces and newlines with a single space
alltext=re.sub('[\n ]+', ' ', soup.text)
text=alltext[1341:-281]
print(text)
# Write the actual content into a file for later use
with open('data/digieco.txt', 'w') as fid:
fid.write(text)
<title>INdoor navigation from CUBesAt TEchnology (INCUBATE) | University of Vaasa</title>
The project will research the application of small satellite technology for precise positioning of indoor spaces and navigation. A new small satellite will also be designed in the project. A sufficiently accurate positioning service that works seamlessly in outdoor and indoor spaces does not currently exist. GPS does not work reliably indoors and between high buildings in cities, not to mention telling the room or floor of the location. – A solution for precise positioning, navigation and timing can be found by utilising LEO small satellites that orbit the earth at a low altitude. They send a stronger signal to the earth than the traditional positioning satellites and orbit the earth faster than them, even in 40 minutes. If proposals about building an internet based on small satellites are realised, there will be about 50,000 active satellites orbiting the earth in ten years, In the three-year INdoor navigation form CUBesAt Technology i.e. INCUBATE research project, the objective is to study how positioning, navigation and timing (PNT) based on small satellites can be used in indoor spaces. The project will also research the commercial potential of the solution and revenue possibilities, partly jointly with companies. The technology developed in the project will offer extensive application potential for many industry sectors. The researchers intend to also develop the use of current small satellites for positioning, as well as new payload, i.e. equipment and software carried by the satellite, to improve navigation solutions. The satellite signal and its reception must be optimised so that a sufficiently high-performing satellite signal can be defined for accurate positioning and navigation. From the University of Vaasa, the Digital Economy research platform headed by Heidi Kuusniemi is involved in the project, as well as the International Business and Marketing research group represented in the project by Arto Ojala, Professor of International Business. Other researchers in the project are Kendall Rutledge and Petri Välisuo, Jani Boutellier and Mohammed Elmusrati, together with their doctoral researchers. The research project led by the University of Vaasa receives funding in the amount of EUR 950,000 from the Building the Future - Taking Action programme of the Centennial Foundation of the Federation of Finnish Technology Industries and Jane and Aatos Erkko Foundation. Project leader: Director, professor Heidi Kuusniemi, Digital Economy -research platform, University of Vaasa More information: Press release Organisation coordinating the project University of Vaasa Project partners Tampereen yliopisto Aalto University National Land Survey of Finland Funding partners Technology Industries of Finland Centennial Foundation
22.2. Split the text into words and sentences#
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
sentences=sent_tokenize(text)
words=word_tokenize(text)
print(len(sentences))
print(len(words))
print(words[:20])
print("")
for i in range(3):
print(i, ":", sentences[i])
17
450
['The', 'project', 'will', 'research', 'the', 'application', 'of', 'small', 'satellite', 'technology', 'for', 'precise', 'positioning', 'of', 'indoor', 'spaces', 'and', 'navigation', '.', 'A']
0 : The project will research the application of small satellite technology for precise positioning of indoor spaces and navigation.
1 : A new small satellite will also be designed in the project.
2 : A sufficiently accurate positioning service that works seamlessly in outdoor and indoor spaces does not currently exist.
22.3. Remove common words#
The text contains plenty of small words, which are common in all texts, and they are not therefore very useful in analyzing the context of a specific piece of text. These stop words are often removed.
Computer usually assumes that lowercase and uppercase are different, but the case does not matter in the meaning of the words. Therefore all words are usually normalized to small case characters before further analysis.
from nltk.corpus import stopwords
stop_words_fin = set(stopwords.words("finnish"))
stop_words = set(stopwords.words("english"))
more = stop_words.union(set(['article', 'link'])) # Extend the list by words you are not interested in
filtered_words=[]
for word in words:
lcword = word.casefold()
# Skip words containing digits (if you like)
if re.match('\d+', lcword):
continue
# Skip stop words and punctuations
if lcword not in stop_words:
filtered_words.append(lcword)
print(len(filtered_words))
filtered_words[:20]
294
['project',
'research',
'application',
'small',
'satellite',
'technology',
'precise',
'positioning',
'indoor',
'spaces',
'navigation',
'.',
'new',
'small',
'satellite',
'also',
'designed',
'project',
'.',
'sufficiently']
22.4. Stemming#
The same word may have different forms, such as design, designing, designs. Stemming means finding the root of the word in order to make the computer to understand that the word is the same, even if it is in different form.
from nltk.stem import PorterStemmer, SnowballStemmer
stemmer = SnowballStemmer(language='english') # Finnish is also supported :)
print(stemmer.stem('designing'), stemmer.stem('designs'), stemmer.stem('design'))
stemmed_words = [stemmer.stem(word) for word in filtered_words]
design design design
print("%20s %20s" % ('Original', 'Stem'))
print(" "*10 + "-"*35)
for i in range(15):
print("%20s %20s" % (filtered_words[i], stemmed_words[i]))
Original Stem
-----------------------------------
project project
research research
application applic
small small
satellite satellit
technology technolog
precise precis
positioning posit
indoor indoor
spaces space
navigation navig
. .
new new
small small
satellite satellit
22.5. Lemmatizing#
Changes words to their basic forms, so that all output words are proper words, not only the stems. Lemma is the basic form of the word, which represents a group of words.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word) for word in filtered_words]
print("%20s, %20s, %20s" % ('Original', 'Stem', 'Lemmatized'))
print(" "*10 + "-"*55)
for i in range(25):
print("%20s, %20s, %20s" % (filtered_words[i], stemmed_words[i], lemmatized_words[i]))
Original, Stem, Lemmatized
-------------------------------------------------------
project, project, project
research, research, research
application, applic, application
small, small, small
satellite, satellit, satellite
technology, technolog, technology
precise, precis, precise
positioning, posit, positioning
indoor, indoor, indoor
spaces, space, space
navigation, navig, navigation
., ., .
new, new, new
small, small, small
satellite, satellit, satellite
also, also, also
designed, design, designed
project, project, project
., ., .
sufficiently, suffici, sufficiently
accurate, accur, accurate
positioning, posit, positioning
service, servic, service
works, work, work
seamlessly, seamless, seamlessly
# The position of the word can be specically adjusted, now as adjective, noun is the default
print(lemmatizer.lemmatize("worst", pos="n"))
print(lemmatizer.lemmatize("worst", pos="a"))
worst
bad
22.6. Finding the parts of speech#
Sanaluokat
nltk.help.upenn_tagset()
DT=Determiner
JJ=Adjective
NN=Noun
MD=Modal auxiliary
RB=Adverb
VB=Verb
VBN=Verb, past participle
WDT=WH determiner
VBZ=Verb, preset tense
…
tags=nltk.pos_tag(words)
tags[:20]
[('The', 'DT'),
('project', 'NN'),
('will', 'MD'),
('research', 'NN'),
('the', 'DT'),
('application', 'NN'),
('of', 'IN'),
('small', 'JJ'),
('satellite', 'NN'),
('technology', 'NN'),
('for', 'IN'),
('precise', 'JJ'),
('positioning', 'NN'),
('of', 'IN'),
('indoor', 'JJ'),
('spaces', 'NNS'),
('and', 'CC'),
('navigation', 'NN'),
('.', '.'),
('A', 'DT')]
# Select all verbs, print first 10
tagsarray=np.array(tags)
i=tagsarray[:,1]=='VB'
tagsarray[i][:10]
array([['be', 'VB'],
['work', 'VB'],
['mention', 'VB'],
['–', 'VB'],
['be', 'VB'],
['orbit', 'VB'],
['be', 'VB'],
['study', 'VB'],
['be', 'VB'],
['offer', 'VB']], dtype='<U15')
# Select all nouns, print first 10
tagsarray=np.array(tags)
i=tagsarray[:,1]=='NN'
tagsarray[i][:10]
array([['project', 'NN'],
['research', 'NN'],
['application', 'NN'],
['satellite', 'NN'],
['technology', 'NN'],
['positioning', 'NN'],
['navigation', 'NN'],
['satellite', 'NN'],
['project', 'NN'],
['positioning', 'NN']], dtype='<U15')
# Select all adjectives, print first 10
tagsarray=np.array(tags)
i=tagsarray[:,1]=='JJ'
tagsarray[i][:10]
array([['small', 'JJ'],
['precise', 'JJ'],
['indoor', 'JJ'],
['new', 'JJ'],
['small', 'JJ'],
['accurate', 'JJ'],
['indoor', 'JJ'],
['high', 'JJ'],
['small', 'JJ'],
['low', 'JJ']], dtype='<U15')
22.7. Parsing grammar#
A simple syntax of a grammar can be defined using a template with syntax resembling regular expressions, as follows:
A noun phrase NP is a sentence which starts with optional determiner DT and can have zero or more adjectives JJ and it must have a noun NN in the end.
The Regexp Parser can use this grammatic rule and find the sentences matching to this rule from the text:
grammar = "NP: {<DT>?<JJ>*<NN>}"
chunk_parser = nltk.RegexpParser(grammar)
tree = chunk_parser.parse(tags[:20])
tree

22.8. Finding named entities#
Named entity recognizer can be used for finding named entities such as persons, organizations, locations, times, facilities or geographical locations (GPE).
#tree = nltk.ne_chunk(pos_tags[140:160])
tree = nltk.ne_chunk(tags[-43:-30])
tree

# List all named entities in the text
ne = nltk.ne_chunk(tags, binary=True)
for e in ne:
if hasattr(e, "label") and e.label() == "NE":
print(e)
(NE GPS/NNP)
(NE LEO/NNP)
(NE INdoor/NNP)
(NE CUBesAt/NNP Technology/NNP)
(NE INCUBATE/NNP)
(NE PNT/NNP)
(NE University/NNP)
(NE Vaasa/NNP)
(NE Digital/NNP Economy/NNP)
(NE Heidi/NNP Kuusniemi/NNP)
(NE International/NNP Business/NNP)
(NE Arto/NNP Ojala/NNP)
(NE International/NNP Business/NNP)
(NE Kendall/NNP Rutledge/NNP)
(NE Petri/NNP Välisuo/NNP)
(NE Jani/NNP Boutellier/NNP)
(NE Mohammed/NNP Elmusrati/NNP)
(NE University/NNP)
(NE Vaasa/NNP)
(NE Future/NNP)
(NE Centennial/NNP Foundation/NNP)
(NE Finnish/NNP Technology/NNP Industries/NNPS)
(NE Jane/NNP)
(NE Aatos/NNP Erkko/NNP Foundation/NNP)
(NE Heidi/NNP Kuusniemi/NNP)
(NE Digital/NNP Economy/NNP)
(NE University/NNP)
(NE Vaasa/NNP More/NNP)
(NE University/NNP)
(NE Vaasa/NNP Project/NNP)
(NE Tampereen/NNP)
(NE Finland/NNP Funding/NNP)
(NE Technology/NNP Industries/NNPS)
(NE Finland/NNP Centennial/NNP Foundation/NNP)
22.9. Corpus#
A text parsed for processing is called as Corpus. The NLTK library includes many corpus for testing, but the final goal is of course to make your own corpus for your own analysis.
A corpus can be created from a plain text file, or a full directory of text files using PlaintextXCorpusReader object.
In the example below, the previously written text file is read as a corpus. The filenames can contain wildcards. You may want to import all text files in the data directory using *.txt instead of a single filename.
from nltk.corpus import PlaintextCorpusReader
digieco=PlaintextCorpusReader('./data/', 'digieco.txt')
text = nltk.Text(word_tokenize(digieco.raw()))
22.9.1. Concordance#
When the corpus is ready, it is easy to run many standard tests, for example to study in which context a certain word is used in the text. This is called as concordance.
# The context of a selected word in the corpus
text.concordance('satellite')
Displaying 5 of 5 matches:
research the application of small satellite technology for precise positioning
paces and navigation . A new small satellite will also be designed in the proje
ipment and software carried by the satellite , to improve navigation solutions
improve navigation solutions . The satellite signal and its reception must be o
hat a sufficiently high-performing satellite signal can be defined for accurate
22.9.2. Collocations#
Another common task is to find words which are often used together. These collocations can be now easily examined:
# Words frequently mentioned together
text.collocations()
indoor spaces; small satellites; Digital Economy; Heidi Kuusniemi;
International Business; Centennial Foundation; Technology Industries;
accurate positioning; precise positioning; satellite signal; small
satellite; research project
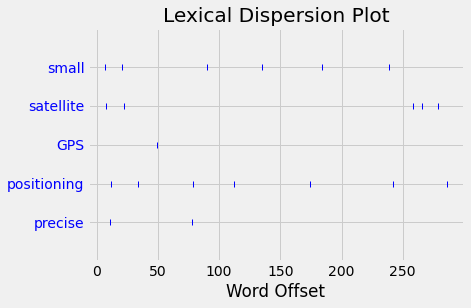
22.9.3. Lexical dispersion#
The dispersion indicates in which location of the document certain word is mentioned. If the corpus contains several documents, it shown in which of them the word is used.
text.dispersion_plot(['small', 'satellite', 'GPS', 'positioning', 'precise'])
22.9.4. Word statistics#
from nltk import FreqDist
frequency_distribution = FreqDist(text)
frequency_distribution.most_common(20)
[('the', 29),
(',', 19),
('of', 16),
('.', 16),
('and', 15),
('in', 11),
('project', 10),
('positioning', 7),
('The', 6),
('research', 6),
('small', 6),
('navigation', 6),
('be', 6),
('satellites', 6),
('will', 5),
('satellite', 5),
('for', 5),
('to', 5),
('by', 5),
('University', 5)]
punctuations=set([',','.','!','?','@', '%', ':', ';'])
unnecessary=stop_words.union(punctuations)
meaningful_words = [word for word in text if word.casefold() not in unnecessary]
lemmatized = [lemmatizer.lemmatize(word) for word in meaningful_words]
frequency_distribution = FreqDist(lemmatized)
frequency_distribution.most_common(20)
[('satellite', 11),
('project', 10),
('positioning', 7),
('research', 6),
('small', 6),
('navigation', 6),
('University', 5),
('earth', 4),
('Vaasa', 4),
('indoor', 3),
('space', 3),
('also', 3),
('solution', 3),
('signal', 3),
('Technology', 3),
('researcher', 3),
('Foundation', 3),
('application', 2),
('technology', 2),
('precise', 2)]
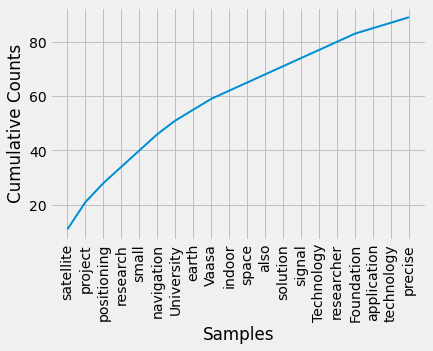
frequency_distribution.plot(20, cumulative=True)
<AxesSubplot:xlabel='Samples', ylabel='Cumulative Counts'>
22.10. Topic modelling#
Now when we have tools to understand language, clean it and prepare for further processing, now we can start the machine learning part. Some plenty of used algorithms for text classification and retrieval are:
Latent Semantic Analysis (LSA/LSI/SVD),
Latent Dirichlet Allocation (LDA)
Random Projections (RP)
Hierarchical Dirichlet Process (HDP)
word2vec deep learning.
At least, these are implemented in a Python library GenSim
Gensim can process large body of texts out of core (all texts do not need to fit in the memory at the same time).
# pip install gensim
# pip install pyLDAvis
import gensim
from gensim import corpora
from pyLDAvis import gensim_models
22.10.1. Preprocessing#
lowercase
remove unnecessary automatically
uva=PlaintextCorpusReader('./data/', ['digieco.txt', 'greta.txt', 'propulsion.txt'])
punctuations=set([',','.','!','?','@', '%', ':', ';'])
unnecessary=stop_words.union(punctuations)
docs=[]
for document in uva.fileids():
tokens = gensim.utils.simple_preprocess(uva.raw(document))
meaningful_words = [word for word in tokens if word not in unnecessary]
lemmatized = [lemmatizer.lemmatize(word) for word in meaningful_words]
docs.append(lemmatized)
print(len(docs))
for i in range(len(docs)):
print(i, docs[i][:10])
3
0 ['project', 'research', 'application', 'small', 'satellite', 'technology', 'precise', 'positioning', 'indoor', 'space']
1 ['project', 'greta', 'aim', 'develop', 'policy', 'tool', 'sustainable', 'smart', 'specialisation', 'innovation']
2 ['led', 'university', 'vaasa', 'significant', 'research', 'consortium', 'aim', 'develop', 'radically', 'new']
22.10.2. Topic mapping example#
The document needs to be encoded as vector of features. For example, a single feature may be thought of as a question-answer pair:
How many times does the word splonge appear in the document? Zero.
How many paragraphs does the document consist of? Two.
How many fonts does the document use? Five.
dictionary = corpora.Dictionary(docs)
dictionary.token2id
{'aalto': 0,
'aatos': 1,
'accurate': 2,
'action': 3,
'active': 4,
'also': 5,
'altitude': 6,
'amount': 7,
'application': 8,
'arto': 9,
'based': 10,
'boutellier': 11,
'building': 12,
'business': 13,
'carried': 14,
'centennial': 15,
'city': 16,
'commercial': 17,
'company': 18,
'coordinating': 19,
'cubesat': 20,
'current': 21,
'currently': 22,
'defined': 23,
'designed': 24,
'develop': 25,
'developed': 26,
'digital': 27,
'director': 28,
'doctoral': 29,
'earth': 30,
'economy': 31,
'elmusrati': 32,
'equipment': 33,
'erkko': 34,
'eur': 35,
'even': 36,
'exist': 37,
'extensive': 38,
'faster': 39,
'federation': 40,
'finland': 41,
'finnish': 42,
'floor': 43,
'form': 44,
'found': 45,
'foundation': 46,
'funding': 47,
'future': 48,
'gps': 49,
'group': 50,
'headed': 51,
'heidi': 52,
'high': 53,
'improve': 54,
'incubate': 55,
'indoor': 56,
'indoors': 57,
'industry': 58,
'information': 59,
'intend': 60,
'international': 61,
'internet': 62,
'involved': 63,
'jane': 64,
'jani': 65,
'jointly': 66,
'kendall': 67,
'kuusniemi': 68,
'land': 69,
'leader': 70,
'led': 71,
'leo': 72,
'location': 73,
'low': 74,
'many': 75,
'marketing': 76,
'mention': 77,
'minute': 78,
'mohammed': 79,
'must': 80,
'national': 81,
'navigation': 82,
'new': 83,
'objective': 84,
'offer': 85,
'ojala': 86,
'optimised': 87,
'orbit': 88,
'orbiting': 89,
'organisation': 90,
'outdoor': 91,
'partly': 92,
'partner': 93,
'payload': 94,
'performing': 95,
'petri': 96,
'platform': 97,
'pnt': 98,
'positioning': 99,
'possibility': 100,
'potential': 101,
'precise': 102,
'press': 103,
'professor': 104,
'programme': 105,
'project': 106,
'proposal': 107,
'realised': 108,
'receives': 109,
'reception': 110,
'release': 111,
'reliably': 112,
'represented': 113,
'research': 114,
'researcher': 115,
'revenue': 116,
'room': 117,
'rutledge': 118,
'satellite': 119,
'seamlessly': 120,
'sector': 121,
'send': 122,
'service': 123,
'signal': 124,
'small': 125,
'software': 126,
'solution': 127,
'space': 128,
'stronger': 129,
'study': 130,
'sufficiently': 131,
'survey': 132,
'taking': 133,
'tampereen': 134,
'technology': 135,
'telling': 136,
'ten': 137,
'three': 138,
'timing': 139,
'together': 140,
'traditional': 141,
'university': 142,
'use': 143,
'used': 144,
'utilising': 145,
'vaasa': 146,
'välisuo': 147,
'well': 148,
'work': 149,
'year': 150,
'yliopisto': 151,
'actor': 152,
'addition': 153,
'aim': 154,
'aiming': 155,
'aligned': 156,
'among': 157,
'analysis': 158,
'area': 159,
'baltic': 160,
'bottom': 161,
'brief': 162,
'bringing': 163,
'bsr': 164,
'build': 165,
'capacity': 166,
'chain': 167,
'challenge': 168,
'circular': 169,
'civil': 170,
'climate': 171,
'closer': 172,
'cluster': 173,
'co': 174,
'commission': 175,
'comparative': 176,
'concluding': 177,
'consequence': 178,
'coordination': 179,
'coordinator': 180,
'council': 181,
'creating': 182,
'creation': 183,
'deal': 184,
'decision': 185,
'defining': 186,
'development': 187,
'discussion': 188,
'dpsir': 189,
'driven': 190,
'driver': 191,
'egd': 192,
'energy': 193,
'enhance': 194,
'environmental': 195,
'established': 196,
'etc': 197,
'eu': 198,
'experience': 199,
'expert': 200,
'fi': 201,
'finding': 202,
'gap': 203,
'goal': 204,
'green': 205,
'greta': 206,
'growth': 207,
'guidance': 208,
'guided': 209,
'hankkeet': 210,
'helix': 211,
'helping': 212,
'http': 213,
'identified': 214,
'innovation': 215,
'institution': 216,
'institutional': 217,
'intervention': 218,
'interview': 219,
'involve': 220,
'involvement': 221,
'issue': 222,
'lars': 223,
'learning': 224,
'main': 225,
'making': 226,
'method': 227,
'model': 228,
'neutrality': 229,
'ostrobothnia': 230,
'package': 231,
'penta': 232,
'perceived': 233,
'phase': 234,
'policy': 235,
'preparation': 236,
'quadruple': 237,
'regarding': 238,
'region': 239,
'regional': 240,
'relevant': 241,
'report': 242,
'requires': 243,
'round': 244,
'sea': 245,
'selected': 246,
'selecting': 247,
'situation': 248,
'smart': 249,
'society': 250,
'specialisation': 251,
'stakeholder': 252,
'strategy': 253,
'studied': 254,
'support': 255,
'supporting': 256,
'sustainable': 257,
'system': 258,
'table': 259,
'target': 260,
'tool': 261,
'transform': 262,
'transformation': 263,
'tutkimus': 264,
'two': 265,
'un': 266,
'univaasa': 267,
'value': 268,
'vision': 269,
'way': 270,
'working': 271,
'www': 272,
'accomplished': 273,
'achieved': 274,
'activity': 275,
'advanced': 276,
'aftertreatment': 277,
'ambitious': 278,
'approach': 279,
'arena': 280,
'art': 281,
'aside': 282,
'assessment': 283,
'biogas': 284,
'bore': 285,
'breaking': 286,
'capability': 287,
'case': 288,
'catalyst': 289,
'clean': 290,
'combined': 291,
'combustion': 292,
'common': 293,
'competition': 294,
'compliance': 295,
'compression': 296,
'consolidated': 297,
'consortium': 298,
'context': 299,
'control': 300,
'controlled': 301,
'cpt': 302,
'demo': 303,
'demonstrate': 304,
'dissemination': 305,
'earlier': 306,
'efficient': 307,
'electric': 308,
'emission': 309,
'end': 310,
'engine': 311,
'evolving': 312,
'facility': 313,
'feasibility': 314,
'finally': 315,
'first': 316,
'framework': 317,
'ghg': 318,
'global': 319,
'grasped': 320,
'ground': 321,
'growing': 322,
'hybridization': 323,
'hydraulic': 324,
'ignition': 325,
'impactful': 326,
'improvement': 327,
'include': 328,
'incremental': 329,
'innovative': 330,
'instrumental': 331,
'laboratory': 332,
'large': 333,
'lead': 334,
'legislation': 335,
'level': 336,
'light': 337,
'limit': 338,
'long': 339,
'major': 340,
'management': 341,
'marine': 342,
'market': 343,
'meeting': 344,
'methodological': 345,
'meu': 346,
'moving': 347,
'need': 348,
'net': 349,
'novel': 350,
'operation': 351,
'pertain': 352,
'plan': 353,
'position': 354,
'power': 355,
'powertrain': 356,
'prepare': 357,
'promising': 358,
'propulsion': 359,
'prototyping': 360,
'providing': 361,
'putting': 362,
'radically': 363,
'range': 364,
'rapid': 365,
'rcci': 366,
'reactivity': 367,
'readiness': 368,
'regulation': 369,
'response': 370,
'responsible': 371,
'road': 372,
'roadmap': 373,
'role': 374,
'secure': 375,
'secures': 376,
'segment': 377,
'several': 378,
'significant': 379,
'stage': 380,
'state': 381,
'supported': 382,
'tailored': 383,
'take': 384,
'technological': 385,
'term': 386,
'thermal': 387,
'tightening': 388,
'towards': 389,
'transition': 390,
'transport': 391,
'trl': 392,
'ultra': 393,
'underlining': 394,
'upgrade': 395,
'vebic': 396,
'wide': 397,
'world': 398,
'worth': 399}
corpus = [dictionary.doc2bow(doc) for doc in docs]
print('Number of unique tokens: %d' % len(dictionary))
print('Number of documents: %d' % len(corpus))
for row in corpus:
print(len(row))
Number of unique tokens: 400
Number of documents: 3
152
134
160
from gensim import models
import pyLDAvis
tfidf = models.TfidfModel(corpus)
words = "satellite communication project".lower().split()
print(tfidf[dictionary.doc2bow(words)])
[(119, 1.0)]
temp = dictionary[0]
# Latent Dirichlet Allocation
id2word = dictionary.id2token
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=10,
random_state=100,
update_every=1,
chunksize=2000,
passes=10,
alpha='auto',
eta = 'auto',
iterations=100,
eval_every=1)
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(lda_model, corpus, dictionary);
/home/petri/venv/python3/lib/python3.9/site-packages/pyLDAvis/_prepare.py:246: FutureWarning: In a future version of pandas all arguments of DataFrame.drop except for the argument 'labels' will be keyword-only
default_term_info = default_term_info.sort_values(
vis
23. Real case#
import glob
# A real case, 115 recent research journal articles about "UWB positioning" from IEEE Explorer
# Bulk downloaded PDF's and converted to text with pdftotext
filenames=[fn.split('/')[-1] for fn in glob.glob('corpus_txt/*.txt')]
uwb=PlaintextCorpusReader('corpus_txt/', filenames)
punctuations=set([',','.','!','?','@', '%', ':', ';'])
morewords=set(['ieee', 'transaction', 'journal', 'vol'])
unnecessary=stop_words.union(punctuations).union(morewords)
docs=[]
for document in uwb.fileids():
tokens = gensim.utils.simple_preprocess(uwb.raw(document))
meaningful_words = [word for word in tokens if word not in unnecessary]
lemmatized = [lemmatizer.lemmatize(word) for word in meaningful_words]
docs.append(lemmatized)
print(len(docs))
for i in range(len(docs)):
print(i, docs[i][:10])
115
0 ['transaction', 'geoscience', 'remote', 'sensing', 'february', 'sar', 'processing', 'without', 'motion', 'measurement']
1 ['sensor', 'august', 'high', 'accuracy', 'indoor', 'localization', 'system', 'application', 'based', 'tightly']
2 ['transaction', 'cybernetics', 'june', 'ultra', 'wideband', 'odometry', 'based', 'cooperative', 'relative', 'localization']
3 ['microwave', 'wireless', 'component', 'letter', 'november', 'ir', 'uwb', 'angle', 'arrival', 'sensor']
4 ['antenna', 'wireless', 'propagation', 'letter', 'march', 'position', 'information', 'indexed', 'classifier', 'improved']
5 ['special', 'section', 'gnss', 'localization', 'navigation', 'technology', 'date', 'current', 'version', 'september']
6 ['transaction', 'instrumentation', 'measurement', 'august', 'resetting', 'approach', 'in', 'uwb', 'sensor', 'fusion']
7 ['transaction', 'mobile', 'computing', 'august', 'algorithm', 'position', 'optimization', 'decentralized', 'localization', 'platform']
8 ['sensor', 'april', 'detection', 'localization', 'people', 'inside', 'vehicle', 'using', 'impulse', 'radio']
9 ['solid', 'state', 'circuit', 'august', 'ir', 'uwb', 'cmos', 'transceiver', 'high', 'data']
10 ['sensor', 'may', 'pdr', 'uwb', 'based', 'positioning', 'shopping', 'cart', 'stef', 'vandermeeren']
11 ['sensor', 'june', 'high', 'precision', 'low', 'cost', 'imu', 'based', 'indoor', 'pedestrian']
12 ['received', 'march', 'accepted', 'april', 'date', 'current', 'version', 'may', 'digital', 'object']
13 ['september', 'sensor', 'signal', 'processing', 'bias', 'compensation', 'uwb', 'ranging', 'pedestrian', 'geolocation']
14 ['transaction', 'instrumentation', 'measurement', 'integrated', 'positioning', 'system', 'unmanned', 'automatic', 'vehicle', 'coal']
15 ['transaction', 'instrumentation', 'measurement', 'feature', 'selection', 'real', 'time', 'nlos', 'identification', 'mitigation']
16 ['received', 'may', 'accepted', 'may', 'date', 'publication', 'may', 'date', 'current', 'version']
17 ['transaction', 'instrumentation', 'measurement', 'december', 'anchor', 'calibration', 'real', 'time', 'measurement', 'localization']
18 ['sensor', 'may', 'low', 'cost', 'in', 'uwb', 'fusion', 'pedestrian', 'tracking', 'system']
19 ['radio', 'frequency', 'identification', 'december', 'ultra', 'low', 'power', 'ultra', 'wide', 'bandwidth']
20 ['caa', 'automatica', 'sinica', 'july', 'indoor', 'in', 'uwb', 'based', 'human', 'localization']
21 ['received', 'november', 'accepted', 'december', 'date', 'publication', 'december', 'date', 'current', 'version']
22 ['received', 'september', 'accepted', 'october', 'date', 'publication', 'october', 'date', 'current', 'version']
23 ['received', 'january', 'accepted', 'january', 'date', 'publication', 'february', 'date', 'current', 'version']
24 ['sensor', 'february', 'multiple', 'vehicle', 'localization', 'using', 'maximum', 'likelihood', 'kalman', 'filtering']
25 ['sensor', 'november', 'motion', 'based', 'separation', 'imaging', 'closely', 'spaced', 'extended', 'target']
26 ['transaction', 'geoscience', 'remote', 'sensing', 'february', 'measurement', 'coordinate', 'cylindrical', 'target', 'using']
27 ['communication', 'letter', 'november', 'uwb', 'channel', 'impulse', 'response', 'de', 'noising', 'method']
28 ['received', 'april', 'accepted', 'may', 'date', 'publication', 'may', 'date', 'current', 'version']
29 ['communication', 'letter', 'october', 'non', 'line', 'sight', 'identification', 'uwb', 'positioning', 'using']
30 ['robotics', 'automation', 'letter', 'april', 'range', 'focused', 'fusion', 'camera', 'imu', 'uwb']
31 ['transaction', 'microwave', 'theory', 'technique', 'august', 'compact', 'high', 'gain', 'high', 'power']
32 ['june', 'sensor', 'signal', 'processing', 'deep', 'learning', 'noncoherent', 'uwb', 'receiver', 'design']
33 ['special', 'section', 'reliability', 'sensor', 'cloud', 'system', 'application', 'scsa', 'received', 'february']
34 ['sensor', 'june', 'uwb', 'based', 'localization', 'system', 'aided', 'inertial', 'sensor', 'underground']
35 ['sensor', 'july', 'improved', 'pdr', 'uwb', 'integrated', 'system', 'indoor', 'navigation', 'application']
36 ['antenna', 'wireless', 'propagation', 'letter', 'january', 'uwb', 'channel', 'compact', 'shape', 'configuration']
37 ['communication', 'letter', 'march', 'los', 'nlos', 'identification', 'indoor', 'uwb', 'positioning', 'based']
38 ['antenna', 'wireless', 'propagation', 'letter', 'april', 'miniaturized', 'ultrawideband', 'half', 'mode', 'vivaldi']
39 ['transaction', 'instrumentation', 'measurement', 'cramer', 'rao', 'lower', 'bound', 'attainment', 'range', 'positioning']
40 ['transaction', 'instrumentation', 'measurement', 'precise', 'indoor', 'positioning', 'based', 'acoustic', 'ranging', 'smartphone']
41 ['transaction', 'control', 'system', 'technology', 'september', 'peer', 'peer', 'relative', 'localization', 'aerial']
42 ['open', 'access', 'ultra', 'wideband', 'signal', 'generation', 'based', 'silicon', 'segmented', 'mach']
43 ['received', 'june', 'accepted', 'june', 'date', 'publication', 'july', 'date', 'current', 'version']
44 ['communication', 'letter', 'january', 'indoor', 'localization', 'reconfigurable', 'intelligent', 'surface', 'teng', 'yue']
45 ['received', 'april', 'accepted', 'april', 'date', 'publication', 'april', 'date', 'current', 'version']
46 ['biomedical', 'health', 'informatics', 'april', 'sleepposenet', 'multi', 'view', 'learning', 'sleep', 'postural']
47 ['special', 'section', 'human', 'driven', 'edge', 'computing', 'hec', 'received', 'march', 'accepted']
48 ['sensor', 'september', 'comparison', 'pedestrian', 'tracking', 'method', 'based', 'foot', 'waist', 'mounted']
49 ['robotics', 'automation', 'letter', 'october', 'heading', 'estimation', 'using', 'ultra', 'wideband', 'received']
50 ['transaction', 'antenna', 'propagation', 'november', 'planar', 'ultra', 'wideband', 'wide', 'scanning', 'dual']
51 ['sensor', 'september', 'emergency', 'positioning', 'method', 'indoor', 'pedestrian', 'non', 'cooperative', 'navigation']
52 ['transaction', 'vehicular', 'technology', 'october', 'indoor', 'outdoor', 'seamless', 'positioning', 'method', 'using']
53 ['transaction', 'instrumentation', 'measurement', 'november', 'error', 'correction', 'ultrawideband', 'ranging', 'juri', 'sidorenko']
54 ['received', 'april', 'accepted', 'may', 'date', 'publication', 'may', 'date', 'current', 'version']
55 ['received', 'december', 'accepted', 'january', 'date', 'publication', 'january', 'date', 'current', 'version']
56 ['transaction', 'instrumentation', 'measurement', 'uwb', 'localization', 'smart', 'factory', 'augmentation', 'method', 'experimental']
57 ['transaction', 'microwave', 'theory', 'technique', 'november', 'adaptive', 'vector', 'method', 'motion', 'compensation']
58 ['radio', 'frequency', 'identification', 'december', 'practical', 'performance', 'comparison', 'decoding', 'method', 'chipless']
59 ['received', 'october', 'accepted', 'october', 'date', 'publication', 'october', 'date', 'current', 'version']
60 ['transaction', 'microwave', 'theory', 'technique', 'november', 'generalization', 'channel', 'micro', 'doppler', 'capacity']
61 ['sensor', 'september', 'uwb', 'simultaneous', 'breathing', 'heart', 'rate', 'detection', 'driving', 'scenario']
62 ['transaction', 'instrumentation', 'measurement', 'low', 'cost', 'indoor', 'real', 'time', 'locating', 'system']
63 ['received', 'july', 'accepted', 'july', 'date', 'publication', 'july', 'date', 'current', 'version']
64 ['special', 'section', 'artificial', 'intelligence', 'cybersecurity', 'received', 'july', 'accepted', 'august', 'date']
65 ['sensor', 'december', 'impact', 'body', 'wearable', 'sensor', 'position', 'uwb', 'ranging', 'timothy']
66 ['transaction', 'industrial', 'informatics', 'december', 'scalability', 'real', 'time', 'capability', 'energy', 'efficiency']
67 ['robotics', 'automation', 'letter', 'july', 'relative', 'position', 'estimation', 'two', 'uwb', 'device']
68 ['antenna', 'wireless', 'propagation', 'letter', 'december', 'miniaturized', 'uhf', 'uwb', 'tag', 'antenna']
69 ['transaction', 'microwave', 'theory', 'technique', 'august', 'synthesis', 'theory', 'ultra', 'wideband', 'bandpass']
70 ['transaction', 'vehicular', 'technology', 'april', 'new', 'quaternion', 'kalman', 'filter', 'based', 'foot']
71 ['received', 'december', 'accepted', 'december', 'date', 'publication', 'december', 'date', 'current', 'version']
72 ['received', 'april', 'accepted', 'may', 'date', 'publication', 'may', 'date', 'current', 'version']
73 ['received', 'september', 'accepted', 'september', 'date', 'publication', 'september', 'date', 'current', 'version']
74 ['transaction', 'vehicular', 'technology', 'october', 'integrated', 'gnss', 'uwb', 'dr', 'vmm', 'positioning']
75 ['special', 'section', 'intelligent', 'data', 'sensing', 'collection', 'dissemination', 'mobile', 'computing', 'received']
76 ['received', 'april', 'accepted', 'april', 'date', 'publication', 'may', 'date', 'current', 'version']
77 ['received', 'june', 'accepted', 'july', 'date', 'publication', 'july', 'date', 'current', 'version']
78 ['communication', 'letter', 'july', 'opportunistic', 'fusion', 'range', 'different', 'source', 'indoor', 'positioning']
79 ['communication', 'survey', 'tutorial', 'third', 'quarter', 'survey', 'indoor', 'localization', 'system', 'technology']
80 ['sensor', 'may', 'novel', 'nlos', 'error', 'compensation', 'method', 'based', 'imu', 'uwb']
81 ['transaction', 'instrumentation', 'measurement', 'september', 'adapted', 'error', 'map', 'based', 'mobile', 'robot']
82 ['received', 'april', 'accepted', 'may', 'date', 'publication', 'may', 'date', 'current', 'version']
83 ['received', 'september', 'accepted', 'october', 'date', 'publication', 'october', 'date', 'current', 'version']
84 ['transaction', 'vehicular', 'technology', 'april', 'multiple', 'target', 'localization', 'behind', 'shaped', 'corner']
85 ['internet', 'thing', 'september', 'distributed', 'tdma', 'mobile', 'uwb', 'network', 'localization', 'yanjun']
86 ['antenna', 'wireless', 'propagation', 'letter', 'may', 'generic', 'spiral', 'mimo', 'array', 'design']
87 ['transaction', 'instrumentation', 'measurement', 'improving', 'positioning', 'accuracy', 'uwb', 'complicated', 'underground', 'nlos']
88 ['received', 'april', 'accepted', 'may', 'date', 'publication', 'may', 'date', 'current', 'version']
89 ['solid', 'state', 'circuit', 'december', 'ir', 'uwb', 'compatible', 'coherent', 'asynchronous', 'polar']
90 ['transaction', 'antenna', 'propagation', 'april', 'assessment', 'limb', 'movement', 'activity', 'using', 'wearable']
91 ['received', 'march', 'accepted', 'march', 'date', 'publication', 'april', 'date', 'current', 'version']
92 ['received', 'november', 'accepted', 'december', 'date', 'publication', 'december', 'date', 'current', 'version']
93 ['transaction', 'instrumentation', 'measurement', 'denoising', 'outlier', 'dropout', 'correction', 'sensor', 'selection', 'range']
94 ['transaction', 'instrumentation', 'measurement', 'october', 'human', 'body', 'shadowing', 'effect', 'uwb', 'based']
95 ['transaction', 'antenna', 'propagation', 'march', 'experimental', 'analysis', 'ultra', 'wideband', 'body', 'body']
96 ['received', 'january', 'accepted', 'february', 'date', 'publication', 'march', 'date', 'current', 'version']
97 ['received', 'february', 'accepted', 'march', 'date', 'publication', 'march', 'date', 'current', 'version']
98 ['transaction', 'antenna', 'propagation', 'july', 'communication', 'improved', 'beam', 'scannable', 'ultra', 'wideband']
99 ['transaction', 'vehicular', 'technology', 'january', 'novel', 'nlos', 'mitigation', 'algorithm', 'uwb', 'localization']
100 ['transaction', 'applied', 'november', 'application', 'improved', 'kalman', 'filter', 'ground', 'positioning', 'system']
101 ['tsinghua', 'science', 'technology', 'issnll', 'pp', 'doi', 'volume', 'number', 'december', 'anchor']
102 ['antenna', 'wireless', 'propagation', 'letter', 'june', 'fdtd', 'empirical', 'exploration', 'human', 'body']
103 ['sensor', 'april', 'in', 'uwb', 'fusion', 'approach', 'adaptive', 'ranging', 'error', 'mitigation']
104 ['sensor', 'december', 'uwb', 'in', 'integrated', 'pedestrian', 'positioning', 'robust', 'indoor', 'environment']
105 ['communication', 'letter', 'october', 'uwb', 'nlos', 'los', 'classification', 'using', 'deep', 'learning']
106 ['solid', 'state', 'circuit', 'february', 'ghz', 'communication', 'ranging', 'vwb', 'transceiver', 'secure']
107 ['internet', 'thing', 'december', 'joint', 'rfid', 'uwb', 'technology', 'intelligent', 'warehousing', 'management']
108 ['internet', 'thing', 'april', 'kalman', 'filter', 'based', 'integration', 'imu', 'uwb', 'high']
109 ['system', 'march', 'wub', 'ip', 'high', 'precision', 'uwb', 'positioning', 'scheme', 'indoor']
110 ['communication', 'letter', 'june', 'cooperative', 'positioning', 'application', 'using', 'gnss', 'carrier', 'phase']
111 ['received', 'march', 'accepted', 'march', 'date', 'publication', 'march', 'date', 'current', 'version']
112 ['transaction', 'vehicular', 'technology', 'september', 'uwb', 'system', 'indoor', 'positioning', 'tracking', 'arbitrary']
113 ['transaction', 'microwave', 'theory', 'technique', 'june', 'mm', 'ghz', 'noise', 'canceling', 'low']
114 ['introduction', 'blas', 'broadcast', 'relative', 'localization', 'clock', 'synchronization', 'dynamic', 'dense', 'multiagent']
text = nltk.Text(word_tokenize(uwb.raw()))
dictionary = corpora.Dictionary(docs)
text.concordance('multilateration')
Displaying 25 of 51 matches:
ultiscale local mapdrift-driven multilateration SAR autofocus using fast polar
n can also be calculated by the multilateration method , if more than three ref
asure of the solvability of the multilateration problem and provides a recursiv
Þ , which is computed using the multilateration algorithm based on the SVD defi
on ) is calculated by using the multilateration algorithm ( see Section 3 ) . T
gorithm ( see Section 3 ) . The multilateration is based on the SVD method [ 23
h true position by means of the multilateration algorithm as well as optimized
y using the LVM algorithm . The multilateration algorithm uses the distances me
. RS , Reference Station . ML , Multilateration . LVM , Levenberg–Marquardt . C
of the points calculated by the multilateration and the DR-LVM algorithm are il
. RS , Reference Station . ML , Multilateration . LVM , Levenberg–Marquardt . C
he ML and LVM algorithms . ML , Multilateration . LVM , Levenberg–Marquardt . F
mpute the position by using the multilateration method based on SVD , whereby t
he estimated position using the multilateration algorithm for all k combination
in a real-world scenario . ML , Multilateration , LVM , Levenberg–Marquardt . C
“ An algebraic solution to the multilateration problem , ” in Proc . Int . Con
sing the accuracy of hyperbolic multilateration systems , ’ ’ IEEE Trans . Aero
ements of several receivers via multilateration , the beacon ’ s position can b
he positioning is derived using multilateration techniques based on least squar
to the explicit solution of the multilateration . This approach can be applied
the ranging measurements ( said multilateration [ 22 ] ) : Ap = b + ε = b where
+ 2ρm ηm − η12 + 2ρ1 η1 are the multilateration uncertainties , defined as a fu
uced by the geometry on the WLS multilateration solution and on the GDoP , and
rtainty of the WLS solution for multilateration in ( 11 ) is entirely described
is in ( 6 ) . In practice , the multilateration is computed in the modified dis
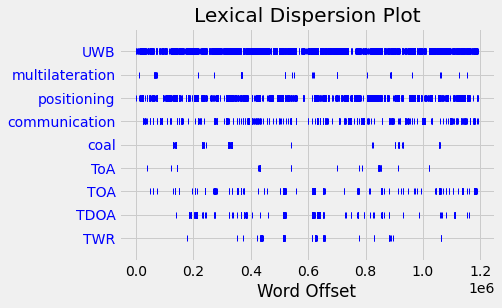
text.dispersion_plot(['UWB', 'multilateration', 'positioning', 'communication', 'coal', 'ToA', 'TOA', 'TDOA', 'TWR'])
corpus = [dictionary.doc2bow(doc) for doc in docs]
print('Number of unique tokens: %d' % len(dictionary))
print('Number of documents: %d' % len(corpus))
Number of unique tokens: 20396
Number of documents: 115
temp = dictionary[0]
# Latent Dirichlet Allocation
id2word = dictionary.id2token
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=10,
random_state=100,
update_every=1,
chunksize=2000,
passes=10,
alpha='auto',
eta = 'auto',
iterations=100,
eval_every=1)
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(lda_model, corpus, dictionary);
/home/petri/venv/python3/lib/python3.9/site-packages/pyLDAvis/_prepare.py:246: FutureWarning: In a future version of pandas all arguments of DataFrame.drop except for the argument 'labels' will be keyword-only
default_term_info = default_term_info.sort_values(
vis
23.1. TF IDF model#
Term Frequency Inverse Document Frequency
from gensim.models import TfidfModel
tf_idf_model = TfidfModel(corpus,id2word=id2word)
# Transformed corpus
tform_corpus = tf_idf_model[corpus]
# Create sparse matrix (design matrix)
spar_matr = gensim.matutils.corpus2csc(tform_corpus)
# Make it to normal matrix
tfidf_matrix = spar_matr.toarray().transpose()
from sklearn.cluster import KMeans
kmodel = KMeans(n_clusters=10)
kmodel.fit(tfidf_matrix)
clusters = kmodel.labels_.tolist()
centroids = kmodel.cluster_centers_.argsort()[:, ::-1] # Sort the words according to their importance.
for i in range(10):
j=i+1
print("Cluster %d words:" % j, end='')
for ind in centroids[i, :10]:
print(' %s' % dictionary.id2token[ind],end=',')
print()
print()
Cluster 1 words: tdc, pulse, gm, cavity, mppm, voltage, bit, smzm, modulator, vwb,
Cluster 2 words: b, bs, lvm, wls, elderly, pdop, configuration, pdoa, wub, dop,
Cluster 3 words: in, pedestrian, pdr, nlos, anchor, particle, imu, walking, foot, lte,
Cluster 4 words: body, rha, anc, wearable, pl, tag, nlos, rl, qlos, shadowing,
Cluster 5 words: array, aperture, ghost, image, pdoa, target, fga, imaging, rx, rps,
Cluster 6 words: uav, robot, anchor, imu, mcl, coal, ij, xa, agvs, xk,
Cluster 7 words: antenna, vivaldi, cp, polarized, tsa, circularly, reflector, uhf, radiation, polarization,
Cluster 8 words: classification, classifier, cnn, capsule, radar, character, ipda, wandering, mwt, rsnrtf,
Cluster 9 words: cnn, lstm, deeptal, gru, tdoa, ρt, ut, layer, nlos, sewio,
Cluster 10 words: twr, agv, node, tag, agent, dln, clock, usv, tdoa, ship,
23.2. What next#
Sentiment analysis