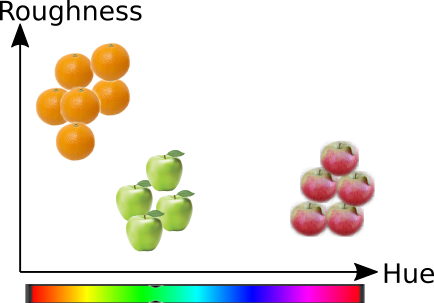
4. Preprocessing and feature extraction#
This module starts actual machine learning part, by introducing some important concepts and walking through and example using classical statistics. Machine learning is more than statistics, but the covered statistical concepts are very important throughout the course.
4.1. Machine Learning#

Fig. 4.1 Machine learning#
4.2. Feature extraction#

Fig. 4.2 Feature Extraction#
The purpose of feature extraction is to capture relevant properties of the samples into variables.
Feature extraction requires domain knowledge and needs to be rethought for every project. It is therefore one of the most time consuming parts of machine learning processes.
4.3. The purpose of machine learning#
Task is to find a function \(f\), which predicts variable \(y_i\) based on \(p\) features \(x_{i,j}\), where \(i \in [0,N]\) and \(j \in [0,P]\).
4.4. Case one, sound recognition#
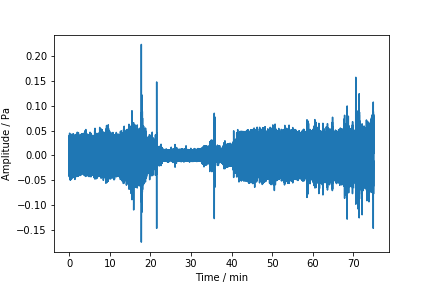
This sound sample contains noise from wind turbine, by-passing cars and some birds perhaps.
Can you find good features to find out what is the dominating noise source in which time?
4.4.1. Perhaps there are differences in the sound pressure level (volume)#
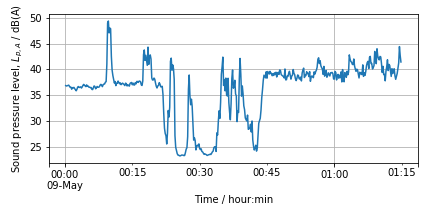
This picture shows the A-weighted sound pressure level (SPL) of the sound signal. It shows what is the subjective volume perceived by a human observer. SPL is a RMS average of the signal over certain time period
where \(p_{rms}\) is the RMS average of the sound pressure, \(p_0=20~\mu\)P, is the reference sound pressure and ,\(T=1\) s, is a time constant.Notice that \(L_p\) is shown in logarithmic scale. Log transformation may sometimes be helpful.
4.4.2. Perhaps studying different spectral components help#
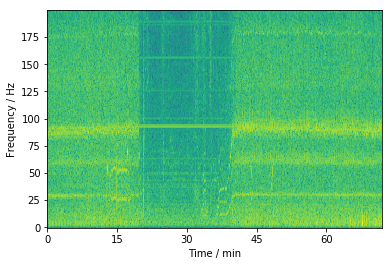
This figure is obtained by splitting the signal in 1 second pieces and applying a Fourier transformation to them, and then by plotting the spectrum of each slice vertically. This method is called as Short Time Fourier Transformation (STFT) and is often usefull method for extracting features from the data.
4.4.3. Other audio features#
Take a look at the feature extraction documentation of the LibRosa library.
4.5. Case 2, What features could be used to classify Iris species?#
Setosa |
Versicolor |
Virginica |
|---|---|---|
|
|
|
Wikimedia Commons |



4.5.1. Features measured by Fisher#
One of the most famos data sets of statistics is the Iris-dataset by Fisher. Let’s take a look what features he measured and how do they perform.
Lets read the data set and plot the head of it.
import numpy as np
import seaborn as sns
sns.set(style='ticks')
iris = sns.load_dataset('iris')
print(iris.shape)
print(iris.describe())
iris
(150, 5)
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
150 rows × 5 columns
4.5.2. Nicer plots with Seaborn#
The Seaborn library is another library for plotting data, in addition to Matplotlib which we used earlier. Seaborn is especially good for statistical plots, mut it has unfortunately totally different API than matplotlib. It may be good to use Matplotlib usually, but it you find some plots inconvenient to be plotted with matplotlib, then it is time to check what seaborn can offer. Easiest way is to check the example gallery to see if someone has made a similar plot what you need, and copy and modify the source code, which is given in the gallery.
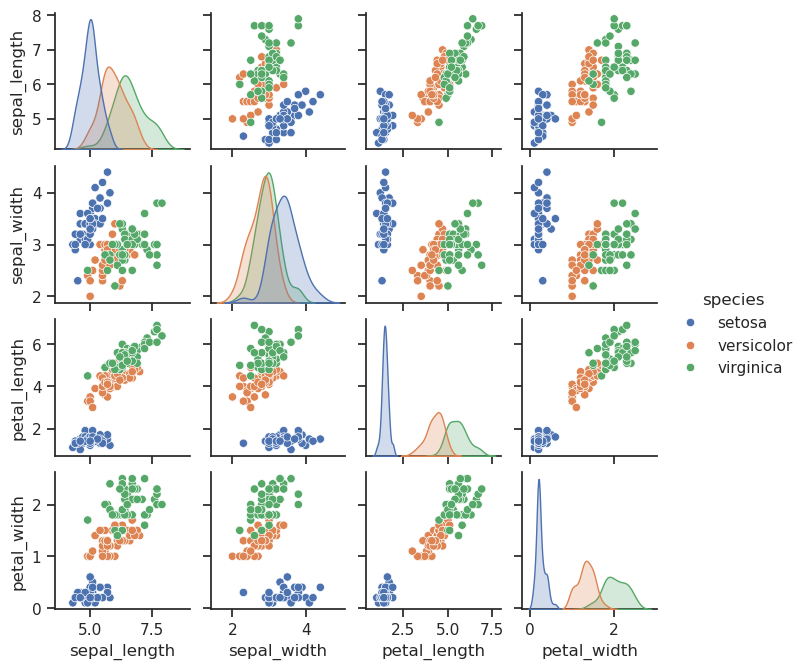
Study the pairplots below, and consider following questions:
Can you separate the three species with only one feature? Can you separate one species with one feature?
Can you separate all three species by combining two features?
Which of the features has the biggest discriminative power (which can separate the different species most efficienty)?
sns.pairplot(iris, hue="species", diag_kind='kde', height=1.7);
We could have used also a scatter matrix from Pandas, but is not as nice.
from pandas.plotting import scatter_matrix
scatter_matrix(iris, alpha=0.2, figsize=(6, 6), diagonal='kde');
4.5.3. Quantitative analysis#
It looks like petal_length can nicely separate Setosa’s from other species, but not necessary Versicolor from Virginica. Lets try to get some numerical proof if this observation is correct.
Lets first study the average feature values and their deviations separately in each group. The groupby() function in pandas dataframe provides very handy methods for implementing this. Groupby kind of splits the original dataframe into three different dataframes according to the species class.
Mean()-function calculates the columnwise mean so in this case it calculates the mean of each feature. Because the dataframe is splitted by species, the result is a matrix, in which each species are in rows, and features in columns. The feature ‘species’, which was used for grouping is removed from the result matrix.
iris.groupby('species').mean()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| species | ||||
| setosa | 5.006 | 3.428 | 1.462 | 0.246 |
| versicolor | 5.936 | 2.770 | 4.260 | 1.326 |
| virginica | 6.588 | 2.974 | 5.552 | 2.026 |
The mean values are different, but are the differences significant. Perhaps studying the overall variation or noise by means of standard deviation would help.
iris.groupby('species').std()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| species | ||||
| setosa | 0.352490 | 0.379064 | 0.173664 | 0.105386 |
| versicolor | 0.516171 | 0.313798 | 0.469911 | 0.197753 |
| virginica | 0.635880 | 0.322497 | 0.551895 | 0.274650 |
It looks like the differences of for example petal_lengths seem to be bigger than the standard deviation. It could be feasible to use it for species recognition.
4.5.4. Visual analysis of mean and distribution using boxplot#
The boxplot displays the median value (the red lines inside the boxes) and distribution as quartiles (the height of the boxes, and lengths of the whiskers) graphically. The box extends from quartile Q1 below to quartile Q3 above the median. The length of the whiskers is 1.5 times the inter quartile range (IQR) from the box edge, where IQR=Q3-Q1. The values outside of whiskers are interpreted as outliers, and they are plotted as circles.
iris.boxplot('petal_length', by='species', figsize=(4,5));
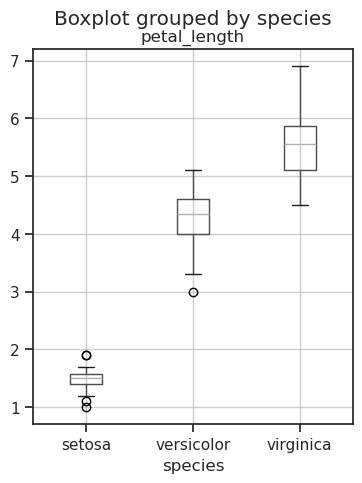
The boxplot shows that Setosa can be separated from Versicolor and Virginica with no confusion, but there is some overlap between Versicolor and Virginica.
4.5.5. Applying an external function to data#
Sometimes it is necessary to apply also such functions to the data, which are not part of the dataframe. It can be accomplished by using the apply-method as follows. Here the median-function from the NumPy-libary is used. You can also apply your own function to the data.
iris.groupby('species').petal_length.apply(np.median)
species
setosa 1.50
versicolor 4.35
virginica 5.55
Name: petal_length, dtype: float64
x=np.array((1,5,3,6,8,4,3,6,2))
np.sort(x)
x
array([1, 5, 3, 6, 8, 4, 3, 6, 2])
def fullRange(x):
"""A function for studying the full range of the vector"""
sortedx=np.sort(x)
return (sortedx[-1] - sortedx[0])
iris.groupby('species').petal_length.apply(fullRange)
species
setosa 0.9
versicolor 2.1
virginica 2.4
Name: petal_length, dtype: float64
4.5.6. Hypothesis testing#
Hypothesis testing is important part of evaluating the data and the models.
In the case of normality testing, the hypothesis is that the data is not normally distributed, and so called zero hypothesis is that it is normally distributed. The purpose of the test is to find out if the data provides enough evidence to safely assume thet the data is not normally distributed. The testing is made so that the deviation of the observed data from the normal distribution is measured and analysed statistically. The result is the probability that the data would deviate from the normal distribution by chance in case where the underlying process is truly normally distributed. This probability is called as p-value. We need to deviate from the normality assumption only when the p-value, is below the threshold a.
The more data we have, the smaller p-value can be obtained. The threshold value to accept the hypothesis is often called \(\alpha\), or a and alpha in this code.
Hypothesis testing is used for many other purposes too, such as testing if the means of two different random variables are truly different or not.

Fig. 4.3 P-value for various tests.#
Typical value for threshold, \(\alpha=0.05\), meaning that we allow only 5% probability to accept the hypothesis by chance.
Let’s formally study if the petal lengts are significantly different or not by forming two hypothesis:
The distribution of petal lengths of Setosa species is different than the distribution of petal lengts of other species
Let’s also assume that the distribution of petal lengts of Versicolor is siginificantly different than that of Virginica
The standard test for these hypothesis is the Student’s T-test.
But the T-test can only be used if the variables are normally distributed. Let’s test that first.
4.5.6.1. Testing if distribution of the variables is normal#
Read more about normality testing methods from Statistics howto
Most often used normality test is the D’Agostino-Pearson Test. It can be taken into use by importing the normaltest function from the stats module of the Scientific Python package.
The zero hypothesis for the normality test is that the data is normally distributed. It can be rejected if we have enough evidence to claim othewise. The normality test uses T-Test to check if the evidence is sufficient for rejecting the null hypothesis.
from scipy.stats import normaltest
normaltest
# Run normality test, and print the output
print(normaltest(iris.petal_length))
# Interpretation, we discard the hypothesis of normal distribution
# if it's probability (the p-value) is less than 95%
alpha=0.05
statistis, pvalue=normaltest(iris.petal_length)
if pvalue<alpha:
print("P-value is very small, we have enough evidence to reject the null hypothesis")
print("Data is not normal distributed")
else:
print("P-value is large, we do not have enough evidence to reject the null hypothesis")
print("Data is normal distributed")
NormaltestResult(statistic=221.68729405585384, pvalue=7.264667501338673e-49)
P-value is very small, we have enough evidence to reject the null hypothesis
Data is not normal distributed
Check it by plotting it
sns.kdeplot(iris.petal_length)
<Axes: xlabel='petal_length', ylabel='Density'>
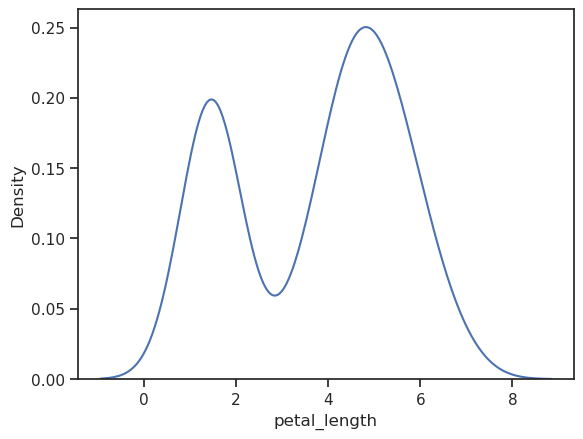
Definitely not normal distribution.
But we were supposed to test this for all species separately
#
# It can be done by grouping the data by species, selecting the petal_lenght
# and applying the normal test to all species separately
results=iris.groupby('species').petal_length.apply(normaltest)
print(results)
if (results[0][1] > alpha): print("Petal length of Setosa is normally distributed")
if (results[1][1] > alpha): print("Petal length of Versicolor is normally distributed")
if (results[2][1] > alpha): print("Petal length of Virginica is normally distributed")
species
setosa (2.236973547672174, 0.32677390349997293)
versicolor (3.3182862415011867, 0.190301976072032)
virginica (2.6991800572037943, 0.2593465635270746)
Name: petal_length, dtype: object
Petal length of Setosa is normally distributed
Petal length of Versicolor is normally distributed
Petal length of Virginica is normally distributed
/tmp/ipykernel_64968/2634370909.py:6: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
if (results[0][1] > alpha): print("Petal length of Setosa is normally distributed")
/tmp/ipykernel_64968/2634370909.py:7: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
if (results[1][1] > alpha): print("Petal length of Versicolor is normally distributed")
/tmp/ipykernel_64968/2634370909.py:8: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
if (results[2][1] > alpha): print("Petal length of Virginica is normally distributed")
sns.kdeplot(iris[iris.species=='setosa'].petal_length)
sns.kdeplot(iris[iris.species=='virginica'].petal_length)
sns.kdeplot(iris[iris.species=='versicolor'].petal_length)
<Axes: xlabel='petal_length', ylabel='Density'>
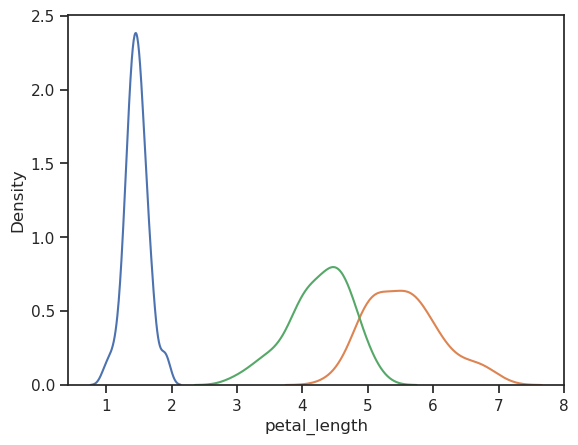
The individual petal lengths seem to be sufficiently normal distributed so that we can use t-test.
4.5.7. Test the similarity of petal_length distributions#
The most often used method for hypothesis testing, is the Student’s T-test, which is also in the stats module of Scientific Python package.
T-Test supports four different confiurations. Read the documentation and select the correct configuration. The selection is quite straightforward.
Two-sided test for the null hypothesis that two independent samples have identical average (expected) values. Example:
p=ttest_ind(a,b)Two-sided test for the null hypothesis that the expected value of a sample of independent observations
ais equal to the given population mean,popmean. Example:p=ttest_1samp(a, popmean)Two-sided test for the null hypothesis that two related or repeated or paired samples have identical average (expected) values. Example:
p=ttest_rel(a,b)Two-sided test for the null hypothesis that 2 independent samples have identical average (expected) values. Example:
ttest_ind_from_stats(mean1, std1, n1, mean2, std2, n2)
Here all tests are two sided, meaning that we do not have any a-priori knowlwdge that one would be bigger than another.
The hypotheses that the two distributions are different is accepted if the probability of getting into that conclusion by chance, \(p\) is smaller than \(\alpha\) =5%:
(p-value\(~<\alpha\), when \(\alpha=0.05\)).
Otherwise we have not evidence for rejecting the null hypothesis that the means are the same.
# T-test of two independent data sets
from scipy.stats import ttest_ind
alpha=0.05
# Test if the petal_lengths of the Setosas are different than the petal_lengths other flowers
test=ttest_ind(iris[iris.species=='setosa'].petal_length, iris[iris.species!='setosa'].petal_length)
print(test)
if test.pvalue < alpha:
print("The petal_length of setosa are statistically different "
+"than the petal_length of other flowers. p=%4.3f" % test.pvalue)
else:
print("The petal_length of setosa are not statistically different "
+"than the petal_length of other flowers: p=%4.3f" % test.pvalue)
# Test if the petal_lengths of Versicolor and Virginia are different
test=ttest_ind(iris[iris.species=='versicolor'].petal_length, iris[iris.species=='virginica'].petal_length)
if test.pvalue < alpha:
print("The petal_lengths of Versicolor and Virginica are statistically different "
+": p=%4.2f" % test.pvalue)
else:
print("The petal_lengths of Versicolor and Virginica are not statistically different "
+": p=%4.2f" % test.pvalue)
TtestResult(statistic=-29.130840211367364, pvalue=3.6233785751774946e-63, df=148.0)
The petal_length of setosa are statistically different than the petal_length of other flowers. p=0.000
The petal_lengths of Versicolor and Virginica are statistically different : p=0.00
4.5.8. Non-parametric testing#
If the data is not normally distributed, then we need to use non-parametric tests instead. One often used is the Mann-Whitney rank-test. Because this test does not assume anything about the shape of the distributions, it usually needs larger sample size to get reliable estimate of p-values. Sample size bigger than 20 for both classes is recommended.
from scipy.stats import mannwhitneyu
print(mannwhitneyu(iris[iris.species=='versicolor'].petal_length, iris[iris.species=='virginica'].petal_length))
MannwhitneyuResult(statistic=44.5, pvalue=9.133544727668256e-17)
The p-value of \(4.56 \cdot 10^{-17} < \alpha\) we can conclude that the difference of the petal lenghts of versicolor and virginica is statistically significant. This is reliable result, since it was not necessary to assume any specifig distribution of feature variables.
4.6. Using features for recognizing species#
Now that we know that petal_lengths are different for each species, can this feature be used in recognizing flowers or classifying flower species?
The following picture shows the position of decision boundary leading to highest precision in classifying Versicolor from Virginica species based on petal length.
Blue curve shows the distribution of petal lengths for Versicolor and red curve the distribution for Virginica
The decision boundary is in the location of the intersection of the distribution curves
ROC-curve is shown on the right hand side.
The red dot shows the point corresponding to the current decision boundary
From the curve it can be read that current decisiong point includes 90% of Versicolors, but it also includes some 12% percent of Virginicas
The sensitivity of the classifier is therefore 90% and specificity is 88%
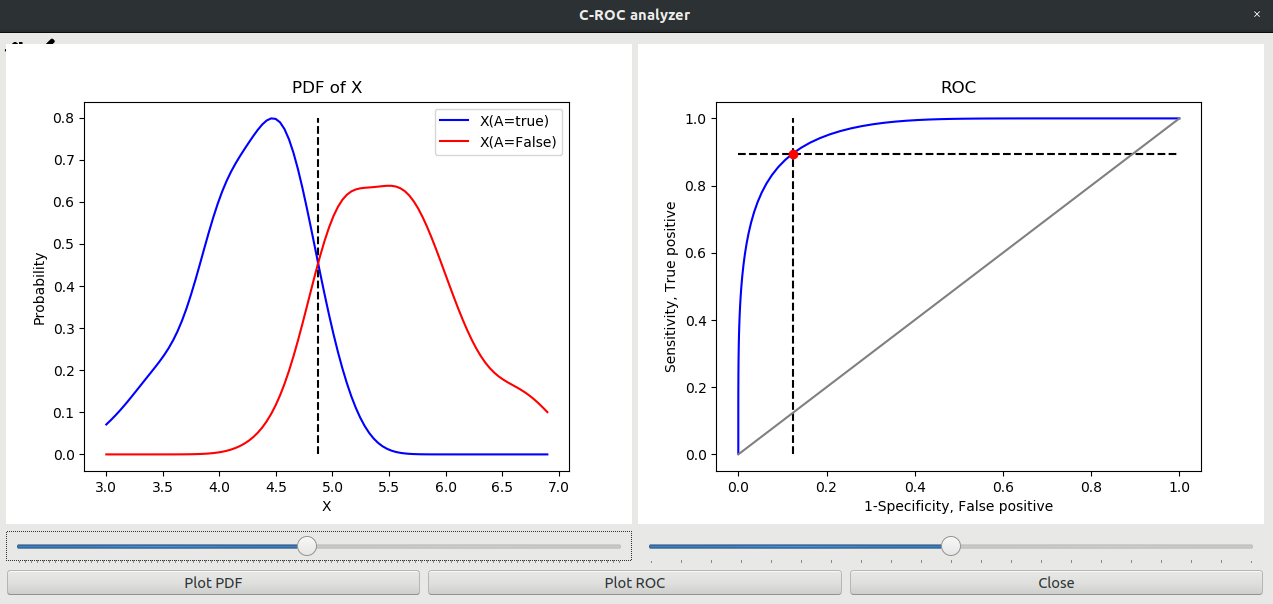
Fig. 4.4 ROC analyzer.#
The ROC curve can be created using following code. Read more from Understanding ROC curves
from scipy.stats import gaussian_kde
import numpy as np
import matplotlib.pyplot as plt
def plotROC(a,b, color='r'):
""" Plots a ROC curve of the one dimensional data whose values
in one case are listed in a, and in another case in b.
"""
## Create a new x-axis, which has for example 100 poinsts
N=100
smallest_value=np.min((a.min(), b.min()))
biggest_value=np.max((a.max(), b.max()))
x_axis=np.linspace(smallest_value, biggest_value, N)
## Estimate the distribution of X using kernel density estimate
## For both cases, 0 and 1 and evaluate their values in the x-axis
## This can be called also as probability density function (PDF).
h0=gaussian_kde(a).evaluate(x_axis)
h1=gaussian_kde(b).evaluate(x_axis)
## Calculate the cumulative distribution function from PDF:s above
## and scale them between 0 and 1
rocx=np.cumsum(h0)/np.sum(h0)
rocy=np.cumsum(h1)/np.sum(h1)
plt.plot(1-rocx, 1-rocy, c=color)
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
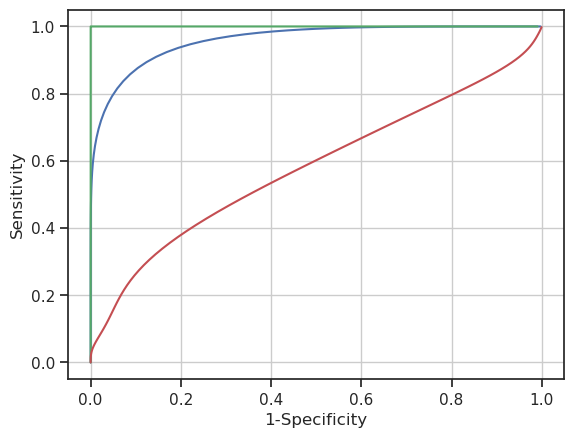
# Can petal length feature be used to distinguish versicolor (see the blue curve)
plotROC(iris[iris.species=='versicolor'].petal_length, iris[iris.species=='virginica'].petal_length, color='b')
# Can pedal length separate setosa from all other species (see the green curve)
plotROC(iris[iris.species=='setosa'].petal_length, iris[iris.species!='setosa'].petal_length, color='g')
# Is sepal width usefull in separating virginica from setosa (red curve)
plotROC(iris[iris.species=='virginica'].sepal_width, iris[iris.species!='virginica'].sepal_width, color='r')
plt.grid()
4.7. How to handle categorial features? #
Features can be
Real values, like floating points or integers, which can be ordered
Categorical features, which is an unordered set of identifiers for separate classes
Because you cannot order the categorical features, they do not have distance metrics either
Many methods rely on distances, and simply using numbers as categories only makes the operation of the predictor worse
Some methods, like Naive Bayesian Classifier (NBC) can use directly categorical features
For many others, it is best to use ns One Hot Encoding, where one binary feature is used to represent each category. Therefore a feature with N-categories will be replaced by a N-bit binary vector.
4.7.1. Example:#
Assume that the species of the Iris is in fact a categorical feature for some ML algorithm. If you would code them just simply like ‘setosa’ -> 1, ‘versicolor’ ->2 and ‘virginica’ -> 3, the ML algorithm could think it as a numerical feature, and use it to calculate distances between species :(
The fix is to use so called One Hot Encoding. Here is the original data:
from sklearn import datasets
import pandas as pd
import numpy as np
iris_dataset=datasets.load_iris()
iris=pd.DataFrame(iris_dataset.data)
iris.columns=iris_dataset.feature_names
iris['species']=[iris_dataset.target_names[i] for i in iris_dataset.target]
iris.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
4.7.2. One hot encoding #
Now we can encode the species to number in a safe way:
Make an encoder and transform the target variable to OneHot format
The categorial variable can be currently encoded as integers, strings or any objects OneHotEncoder reads it in the for nxp matrix, where n is number of samples and p is the number of features to be encoded.
Originally target was such kind of numpy array, which do not have the second index at all. It has to be (unfortunately) converted to column vector, which is otherwise the same, but it has also the second axis, which has only one value, a nx1 array.
This can be done by just simply adding a new dimension into the array, using np.newaxis constant or by using reshape function.
print(iris_dataset.target_names)
iris_dataset.target
# Convert row vector to column vector, by adding the second axis
#iris_dataset.target[:,np.newaxis]
['setosa' 'versicolor' 'virginica']
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
iris.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
from sklearn.preprocessing import OneHotEncoder
# Change to One hot encoding
# Add a new column for each species
for name in iris_dataset.target_names:
iris[name]=0
# The result of the One hot encoding is a sparse matrix, which can be converted to numpy
# array using toarray method:
enc=OneHotEncoder(categories='auto')
iris.loc[:,'setosa':'virginica']=enc.fit_transform(iris_dataset.target[:,np.newaxis]).toarray()
#iris.loc[:,'setosa':'virginica']=enc.fit_transform(iris_dataset.target.reshape(150,1)).toarray()
iris.sample(10)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species | setosa | versicolor | virginica | |
|---|---|---|---|---|---|---|---|---|
| 98 | 5.1 | 2.5 | 3.0 | 1.1 | versicolor | 0 | 1 | 0 |
| 70 | 5.9 | 3.2 | 4.8 | 1.8 | versicolor | 0 | 1 | 0 |
| 109 | 7.2 | 3.6 | 6.1 | 2.5 | virginica | 0 | 0 | 1 |
| 66 | 5.6 | 3.0 | 4.5 | 1.5 | versicolor | 0 | 1 | 0 |
| 123 | 6.3 | 2.7 | 4.9 | 1.8 | virginica | 0 | 0 | 1 |
| 119 | 6.0 | 2.2 | 5.0 | 1.5 | virginica | 0 | 0 | 1 |
| 137 | 6.4 | 3.1 | 5.5 | 1.8 | virginica | 0 | 0 | 1 |
| 132 | 6.4 | 2.8 | 5.6 | 2.2 | virginica | 0 | 0 | 1 |
| 38 | 4.4 | 3.0 | 1.3 | 0.2 | setosa | 1 | 0 | 0 |
| 122 | 7.7 | 2.8 | 6.7 | 2.0 | virginica | 0 | 0 | 1 |
# This way you can check the results of the one hot encoding
#enc.fit_transform(iris_dataset.target[:,np.newaxis]).toarray()
4.8. What was learned?#
Some mesured values (petal and sepal widhts and heights in this case) can be used as features, describing the similarities and differences of the samples
T-test can be used for testing if the values of the features are the same or different for different classes of samples. If the features are not significantly different, they are not usefull for classification.
T-test can only be used if the variables are normally distributed.
Non-parametric tests can be used if the data is not normally distributed, but it may need larger sample size
ROC curves form a systematic framework to study the power of the feature in general
Categorical features often need special care, like one hot endoding
Now we can be certain, that the petal lengts are different in all species, and the difference is statistically significant, meaning that they are not different only by chance.